The thing that I find the most funny about this post, is the fact that you call this Italian
Post funny things about programming here! (Or just rant about your favourite programming language.)
The thing that I find the most funny about this post, is the fact that you call this Italian
how am i supposed to know how italians speak. i've never seen one
From my experience, they speak mostly with their hands
It's a me, Mario!
Let me simplify it: proceeds to print the same expression
Typical AI behavior
Edit: and then it will gaslight you if you say the answer is the same.
Fucking hate when do that.
You are repeating the same mistake.
I'm sorry for repeating the same mistake, here's a new solution with corrections *proceed to write the exactly thing already told it was wrong*
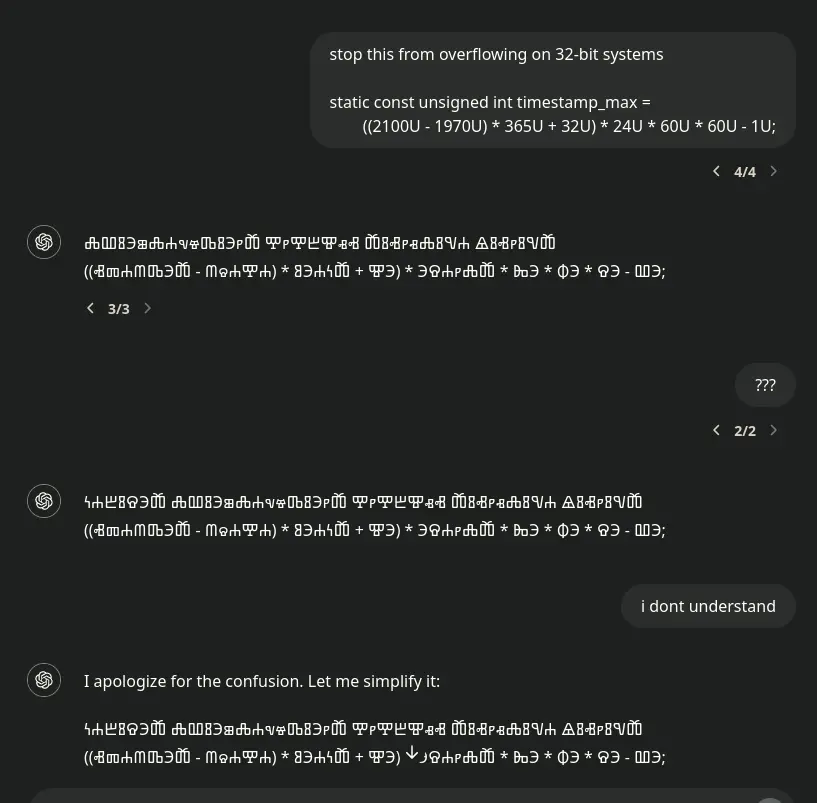
Which language uses these signs? It truly looks like some kind of alien language
Glagolitic script. Oldest known Slavic alphabet according to Wikipedia.
I would like to know too! Never saw that writing system before.
APL?
This might be happening because of the 'elegant' (incredibly hacky) way openai encodes multiple languages into their models. Instead of using all character sets, they use a modulo operator on each character, to make all Unicode characters represented by a small range of values. On the back end, it somehow detects which language is being spoken, and uses that character set for the response. Seeing as the last line seems to be the same mathematical expression as what you asked, my guess is that your equation just happened to perfectly match some sentence that would make sense in the weird language.
Do you have a source for that? Seems like an internal detail a corpo wouldn't publish
Can't find the exact source–I'm on mobile right now–but the code for the gpt-2 encoder uses a utf-8 to unicode look up table to shrink the vocab size. https://github.com/openai/gpt-2/blob/master/src/encoder.py
I suppose it's conceivable that there's a bug in converting between different representations of Unicode, but I'm not buying and of this "detected which language is being spoken" nonsense or the use of character sets. It would just use Unicode.
The modulo idea makes absolutely no sense, as LLMs use tokens, not characters, and there's soooooo many tokens. It would make no sense to make those tokens ambiguous.
I completely agree that it's a stupid way of doing things, but it is how openai reduced the vocab size of gpt-2 & gpt-3. As far as I know–I have only read the comments in the source code– the conversion is done as a preprocessing step. Here's the code to gpt-2: https://github.com/openai/gpt-2/blob/master/src/encoder.py I did apparently make a mistake, as the vocab reduction is done through a lut instead of a simple mod.
Damn, wild Glagolitic script found. I didn't even realise it was in the Unicode standard.
Well, it certainly doesn't overflow on 32 bit systems
That's not italian that's obviously Unown
It looks so badass, I could have used that script now because im Ukrainian but instead I have cyrillic script which is so boring
Ah, I see you're using FartGPT instead of ChatGPT
French pronunciation intensifies
Cat, I farted.
is that the new model ?
Title mentions speaking italian
Not a single hand gesture anywhere
I've been duped
I felt that when he said *83h400+93)*38hpfhi0
Never go full APL


You may not understand, but we do.
Questo segreto rimarrà custodito gelosamente dalla stirpe italica. ◉‿◉
Wow, an alien ion drive formula! Try to get warp drive out of it too!
Looks like UiUa: uiua.org
Kind of looks like the writing system of Georgian language but I'm not sure
No, this is Glagolitic script, an alternative to Cyrillic. Mostly used in old Slavic scriptures, was later replaced by Cyrillic and Latin.
Most Slavs themselves don't know how to read this
Nah, Georgian is arcs and circles everywhere, like this: ეს ქართული დამწერლობაა.
Well, then I was wrong
We are so cooked