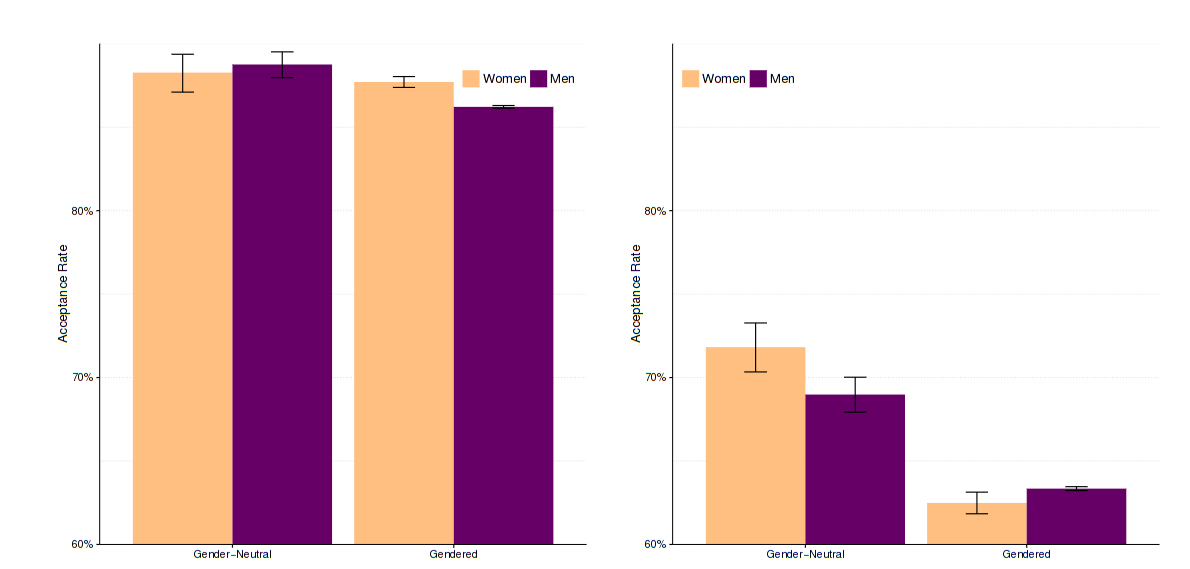
86
Does anybody actually use trunk based development in their company?
(trunkbaseddevelopment.com)
I've heard it thrown around in professional circles and how everybody's doing it wrong, so.. who actually does use it?
For smaller teams
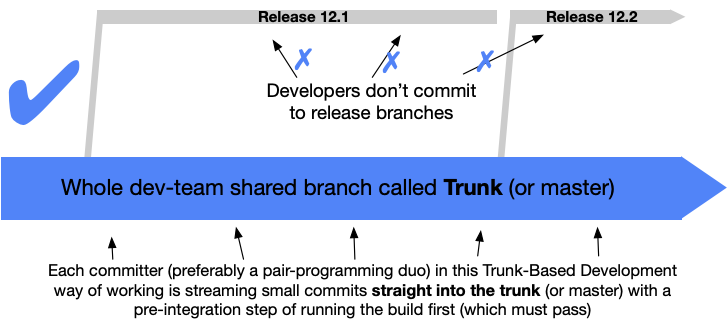
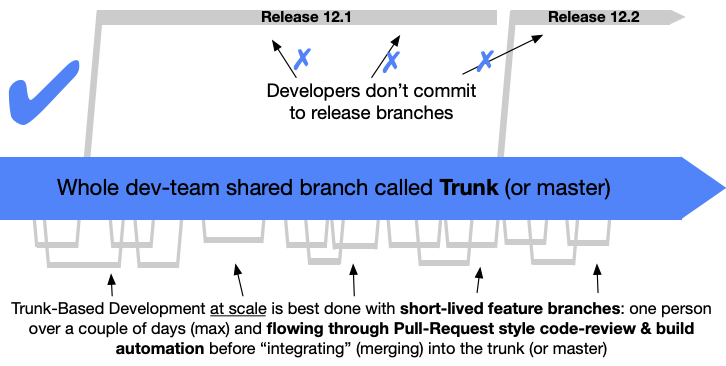
"scaled" trunk based development

What a joke. A sovereign cloud in the EU has to be owned by an EU company without ties to foreign entities, especially those that hose data or other services for it.
AWS's "foreign cloud" will just be another AI training pot for the NSA.
Anti Commercial-AI license