

Another day, another update.
More troubleshooting was done today. What did we do:
- Yesterday evening @phiresky@[email protected] did some SQL troubleshooting with some of the lemmy.world admins. After that, phiresky submitted some PRs to github.
- @[email protected] created a docker image containing 3PR's: Disable retry queue, Get follower Inbox Fix, Admin Index Fix
- We started using this image, and saw a big drop in CPU usage and disk load.
- We saw thousands of errors per minute in the nginx log for old clients trying to access the websockets (which were removed in 0.18), so we added a
return 404in nginx conf for/api/v3/ws. - We updated lemmy-ui from RC7 to RC10 which fixed a lot, among which the issue with replying to DMs
- We found that the many 502-errors were caused by an issue in Lemmy/markdown-it.actix or whatever, causing nginx to temporarily mark an upstream to be dead. As a workaround we can either 1.) Only use 1 container or 2.) set ~~
proxy_next_upstream timeout;~~max_fails=5in nginx.
Currently we're running with 1 lemmy container, so the 502-errors are completely gone so far, and because of the fixes in the Lemmy code everything seems to be running smooth. If needed we could spin up a second lemmy container using the ~~proxy_next_upstream timeout;~~ max_fails=5 workaround but for now it seems to hold with 1.
Thanks to @[email protected] , @[email protected] , @[email protected], @[email protected] , @[email protected] , @[email protected] for their help!
And not to forget, thanks to @[email protected] and @[email protected] for their continuing hard work on Lemmy!
And thank you all for your patience, we'll keep working on it!
Oh, and as bonus, an image (thanks Phiresky!) of the change in bandwidth after implementing the new Lemmy docker image with the PRs.
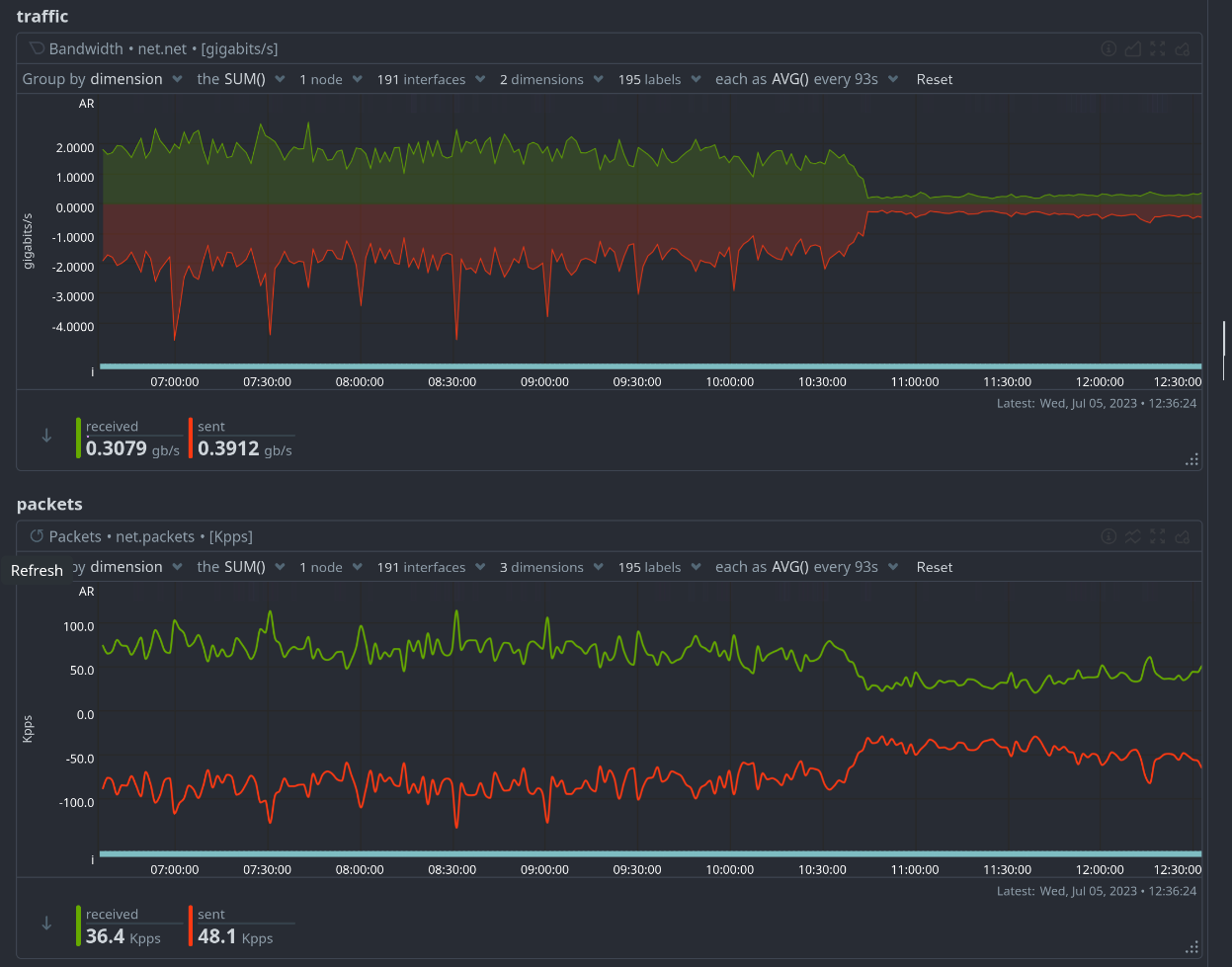
Edit So as soon as the US folks wake up (hi!) we seem to need the second Lemmy container for performance. So that's now started, and I noticed the proxy_next_upstream timeout setting didn't work (or I didn't set it properly) so I used max_fails=5 for each upstream, that does actually work.
server load is too low, everyone upvote more stuff so i can optimize more
edit: guess there is some more work to be done 😁
Upvote causes an endless spinner on Liftoff. 😁
I'm getting 504 gateway time outs when I try to upvote
For me it works way better than before
seems like it may have been a temporary issue. It's clearing back up.
It doesn't for me actually. Maybe just on Lemmy.world?
I don't understand your graph. It says you are measuring gigabit/sec but shouldn't the true performance rating be gigabeans/sec for a Lemmy instance?
And where's the statistics for days between each core dump? A healthy instance should have at least three days between each one
Depends on whether they have fiber or not.
I see what you did there.
Beans have tons of fiber!!
heh
aye aye sir, to the upvote machine!
Double the image upload size and you will see more shitposts
I was gonna argue that you'd see more bean posts, but at this point they're the same thing, both in the pun sense and the literal sense
Web-ui is very smooth rn.. is this .world?
😅
Joke aside, the improvement is like heaven and earth. Love it!. Good work teams!
I'm on another instance, but here's some federated activity for you.
All hail @[email protected]! Today is your day. You have made the single most valuable contribution and you must be celebrated! Bravo! Hurrah!
I was just going to post a meme about choosing either creating activity or spare the server from overloading. Now the joke won't stick.