1926
Technology
34728 readers
270 users here now
This is the official technology community of Lemmy.ml for all news related to creation and use of technology, and to facilitate civil, meaningful discussion around it.
Ask in DM before posting product reviews or ads. All such posts otherwise are subject to removal.
Rules:
1: All Lemmy rules apply
2: Do not post low effort posts
3: NEVER post naziped*gore stuff
4: Always post article URLs or their archived version URLs as sources, NOT screenshots. Help the blind users.
5: personal rants of Big Tech CEOs like Elon Musk are unwelcome (does not include posts about their companies affecting wide range of people)
6: no advertisement posts unless verified as legitimate and non-exploitative/non-consumerist
7: crypto related posts, unless essential, are disallowed
founded 5 years ago
MODERATORS
1927
1928
1929
1930
11
New AI/LLM Breakthrough - FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
(lemmy.world)
cross-posted from: https://lemmy.world/post/1709025
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
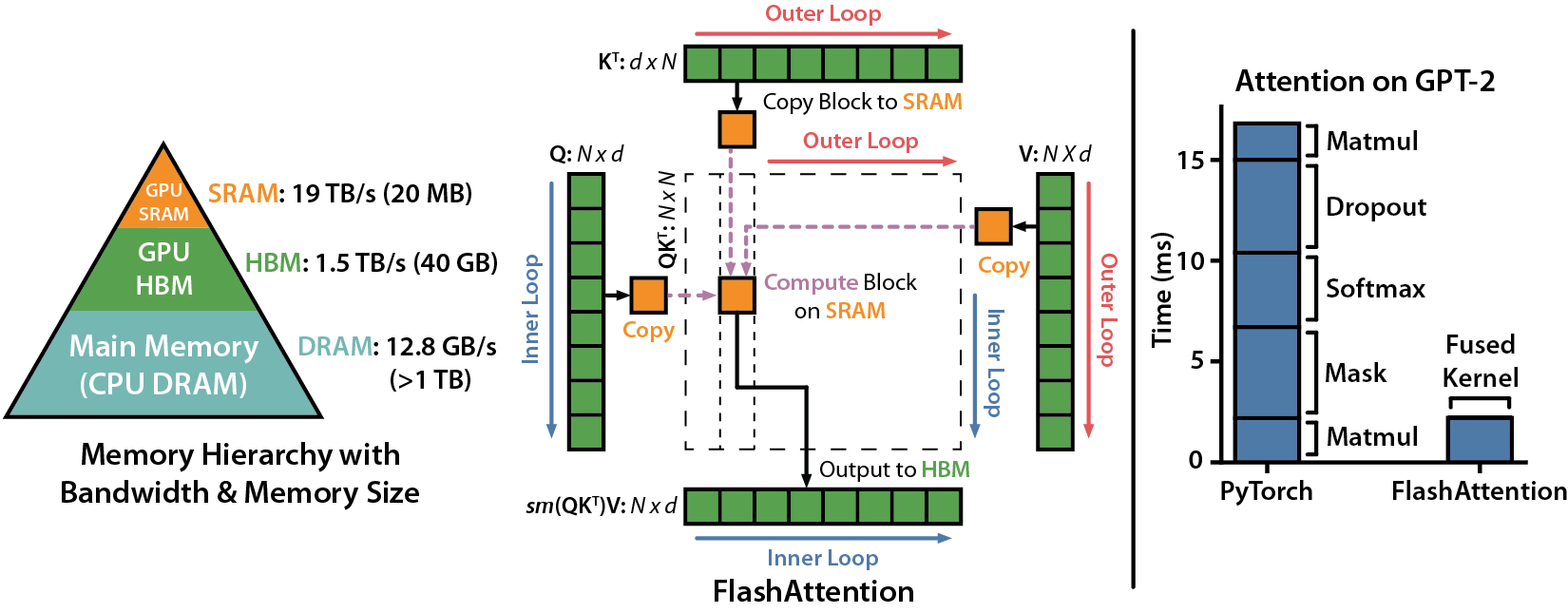
Today, we explore an exciting new development: FlashAttention-2, a breakthrough in Transformer model scaling and performance. The attention layer, a key part of Transformer model architecture, has been a bottleneck in scaling to longer sequences due to its runtime and memory requirements. FlashAttention-2 tackles this issue by improving work partitioning and parallelism, leading to significant speedups and improved efficiency for many AI/LLMs.
The significance of this development is huge. Transformers are fundamental to many current machine learning models, used in a wide array of applications from language modeling to image understanding and audio, video, and code generation. By making attention algorithms IO-aware and improving work partitioning, FlashAttention-2 gets closer to the efficiency of General Matrix to Matrix Multiplication (GEMM) operations, which are highly optimized for modern GPUs. This enables the training of larger and more complex models, pushing the boundaries of what's possible with machine learning both at home and in the lab.
Features & Advancements
FlashAttention-2 improves upon its predecessor by tweaking the algorithm to reduce the number of non-matrix multiplication FLOPs, parallelizing the attention computation, and distributing work within each thread block. These improvements lead to approximately 2x speedup compared to FlashAttention, reaching up to 73% of the theoretical maximum FLOPs/s.
Relevant resources:
Installation & Requirements
To install FlashAttention-2, you'll need CUDA 11.4 and PyTorch 1.12 or above. The installation process is straightforward and can be done through pip or by compiling from source. Detailed instructions are provided on the Github page.
Relevant resources:
Supported Hardware & Datatypes
FlashAttention-2 currently supports Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing GPUs (T4, RTX 2080) is coming soon. It supports datatype fp16 and bf16 (bf16 requires Ampere, Ada, or Hopper GPUs). All head dimensions up to 256 are supported.
Relevant resources:
The/CUT
FlashAttention-2 is a significant leap forward in Transformer model scaling. By improving the efficiency of the attention layer, it allows for faster and more efficient training of larger models. This opens up new possibilities in machine learning applications, especially in systems or projects that need all the performance they can get.
Take Three: Three big takeaways from this post:
Performance Boost: FlashAttention-2 is a significant improvement in Transformer architecture and provides a massive performance boost to AI/LLM models who utilize it. It manages to achieve a 2x speedup compared to its predecessor, FlashAttention. This allows for faster training of larger and more complex models, which can lead to breakthroughs in various machine learning applications at home (and in the lab).
Efficiency and Scalability: FlashAttention-2 improves the efficiency of attention computation in Transformers by optimizing work partitioning and parallelism. This allows the model to scale to longer sequence lengths, increasing its applicability in tasks that require understanding of larger context, such as language modeling, high-resolution image understanding, and code, audio, and video generation.
Better Utilization of Hardware Resources: FlashAttention-2 is designed to be IO-aware, taking into account the reads and writes between different levels of GPU memory. This leads to better utilization of hardware resources, getting closer to the efficiency of optimized matrix-multiply (GEMM) operations. It currently supports Ampere, Ada, or Hopper GPUs and is planning to extend support for Turing GPUs soon. This ensures that a wider range of machine learning practitioners and researchers can take advantage of this breakthrough.
Links
If you found anything about this post interesting - consider subscribing to [email protected] where I do my best to keep you informed in free open-source artificial intelligence.
Thank you for reading!
1931
1932
1933
1934
1935
1936
1937
1938
1939
1940
262
Musk says a 50% drop in ad revenue for Twitter is causing negative cash flow
(www.phonearena.com)
1941
1942
1943
1944
1945
1946
1947
cross-posted from: https://lemmy.world/post/1535820
I'd like to share with you Petals: decentralized inference and finetuning of large language models
- https://petals.ml/
- https://research.yandex.com/blog/petals-decentralized-inference-and-finetuning-of-large-language-models
Run large language models at home, BitTorrent‑style
Run large language models like LLaMA-65B, BLOOM-176B, or BLOOMZ-176B collaboratively — you load a small part of the model, then team up with people serving the other parts to run inference or fine-tuning. Single-batch inference runs at 5-6 steps/sec for LLaMA-65B and ≈ 1 step/sec for BLOOM — up to 10x faster than offloading, enough for chatbots and other interactive apps. Parallel inference reaches hundreds of tokens/sec. Beyond classic language model APIs — you can employ any fine-tuning and sampling methods, execute custom paths through the model, or see its hidden states. You get the comforts of an API with the flexibility of PyTorch.
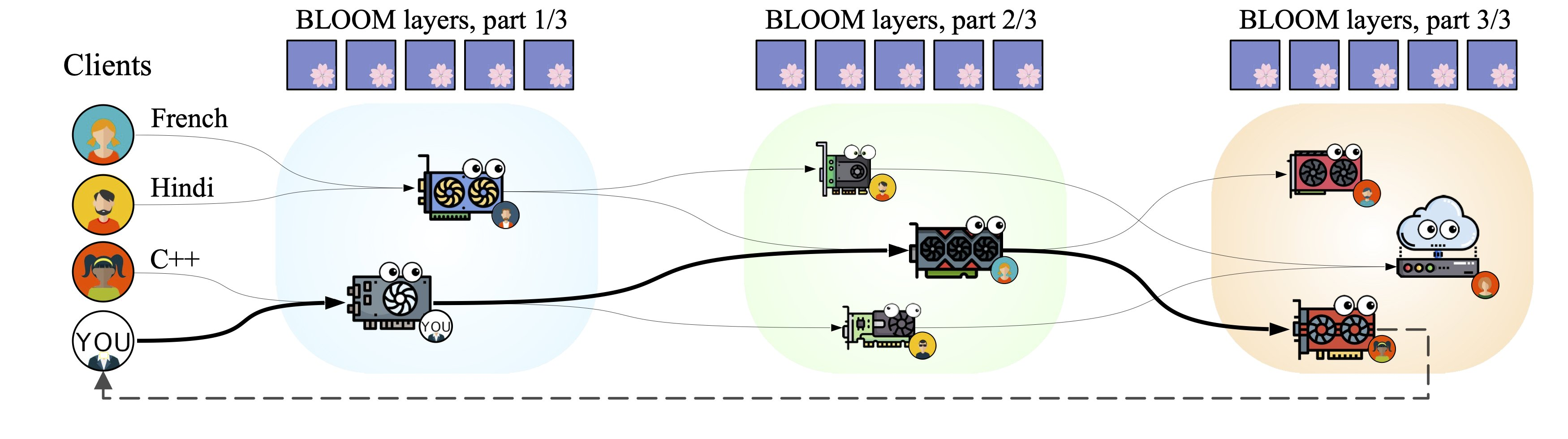
Overview of the Approach
On a surface level, Petals works as a decentralized pipeline designed for fast inference of neural networks. It splits any given model into several blocks (or layers) that are hosted on different servers. These servers can be spread out across continents, and anybody can connect their own GPU! In turn, users can connect to this network as a client and apply the model to their data. When a client sends a request to the network, it is routed through a chain of servers that is built to minimize the total forward pass time. Upon joining the system, each server selects the most optimal set of blocks based on the current bottlenecks within the pipeline. Below, you can see an illustration of Petals for several servers and clients running different inputs for the model.
Benchmarks
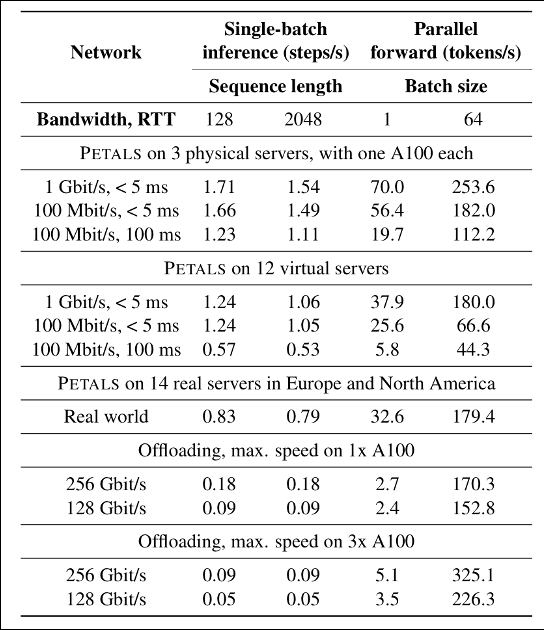
We compare the performance of Petals with offloading, as it is the most popular method for using 100B+ models on local hardware. We test both single-batch inference as an interactive setting and parallel forward pass throughput for a batch processing scenario. Our experiments are run on BLOOM-176B and cover various network conditions, from a few high-speed nodes to real-world Internet links. As you can see from the table below, Petals is predictably slower than offloading in terms of throughput but 3–25x faster in terms of latency when compared in a realistic setup. This means that inference (and sometimes even finetuning) is much faster with Petals, despite the fact that we are using a distributed model instead of a local one.
Conclusion
Our work on Petals continues the line of research towards making the latest advances in deep learning more accessible for everybody. With this work, we demonstrate that it is feasible not only to train large models with volunteer computing, but to run their inference in such a setup as well. The development of Petals is an ongoing effort: it is fully open-source (hosted at https://github.com/bigscience-workshop/petals), and we would be happy to receive any feedback or contributions regarding this project!
1948
1949
1950
