I was pleasantly surprised by many models of the Deepseek family. Verbose, but in a good way? At least that was my experience. Love to see it mentioned here.
Meta has released and open-sourced Llama 3.1 in three different sizes: 8B, 70B, and 405B
This new Llama iteration and update brings state-of-the-art performance to open-source ecosystems.
If you've had a chance to use Llama 3.1 in any of its variants - let us know how you like it and what you're using it for in the comments below!
Llama 3.1 Megathread
For this release, we evaluated performance on over 150 benchmark datasets that span a wide range of languages. In addition, we performed extensive human evaluations that compare Llama 3.1 with competing models in real-world scenarios. Our experimental evaluation suggests that our flagship model is competitive with leading foundation models across a range of tasks, including GPT-4, GPT-4o, and Claude 3.5 Sonnet. Additionally, our smaller models are competitive with closed and open models that have a similar number of parameters.
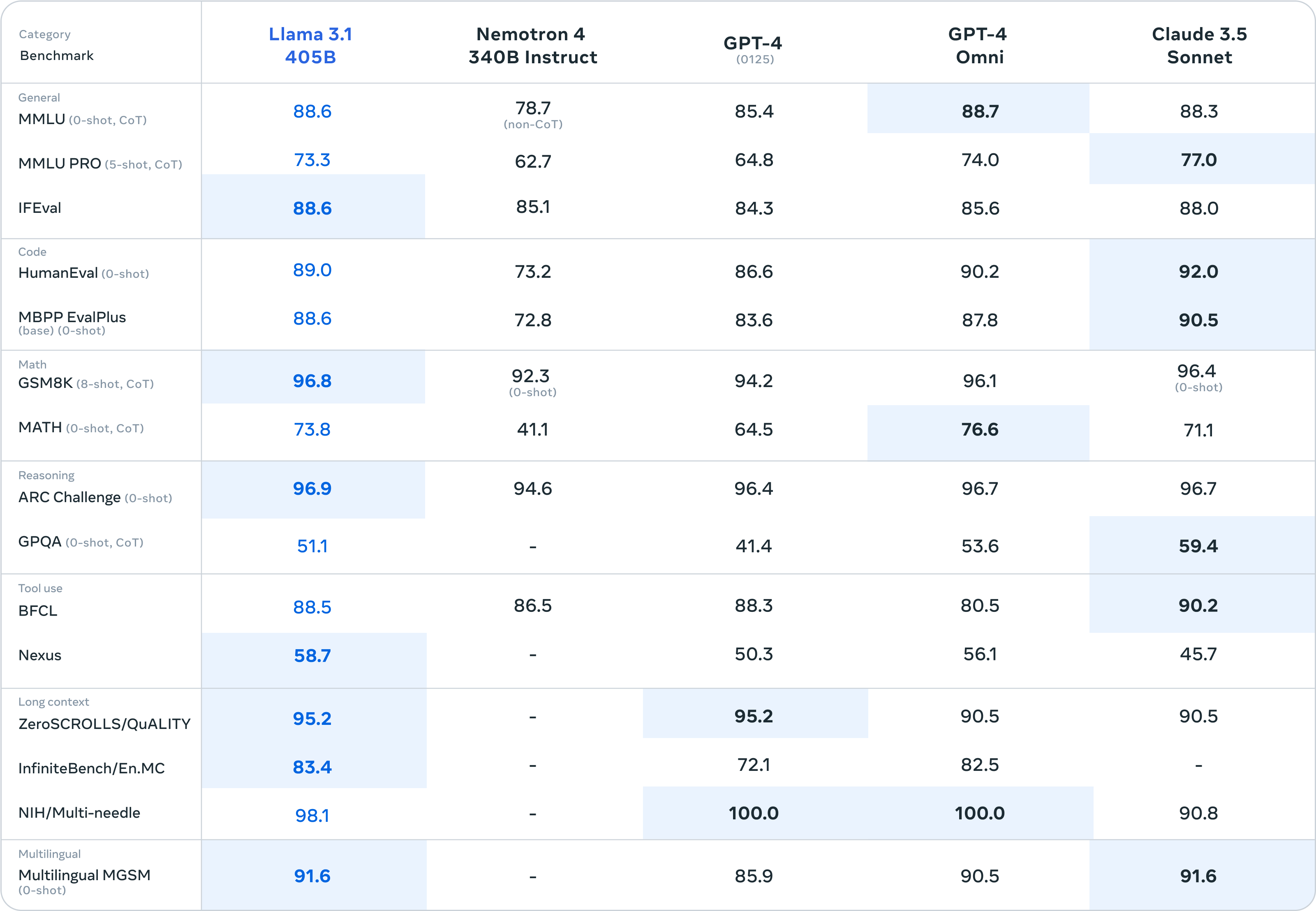
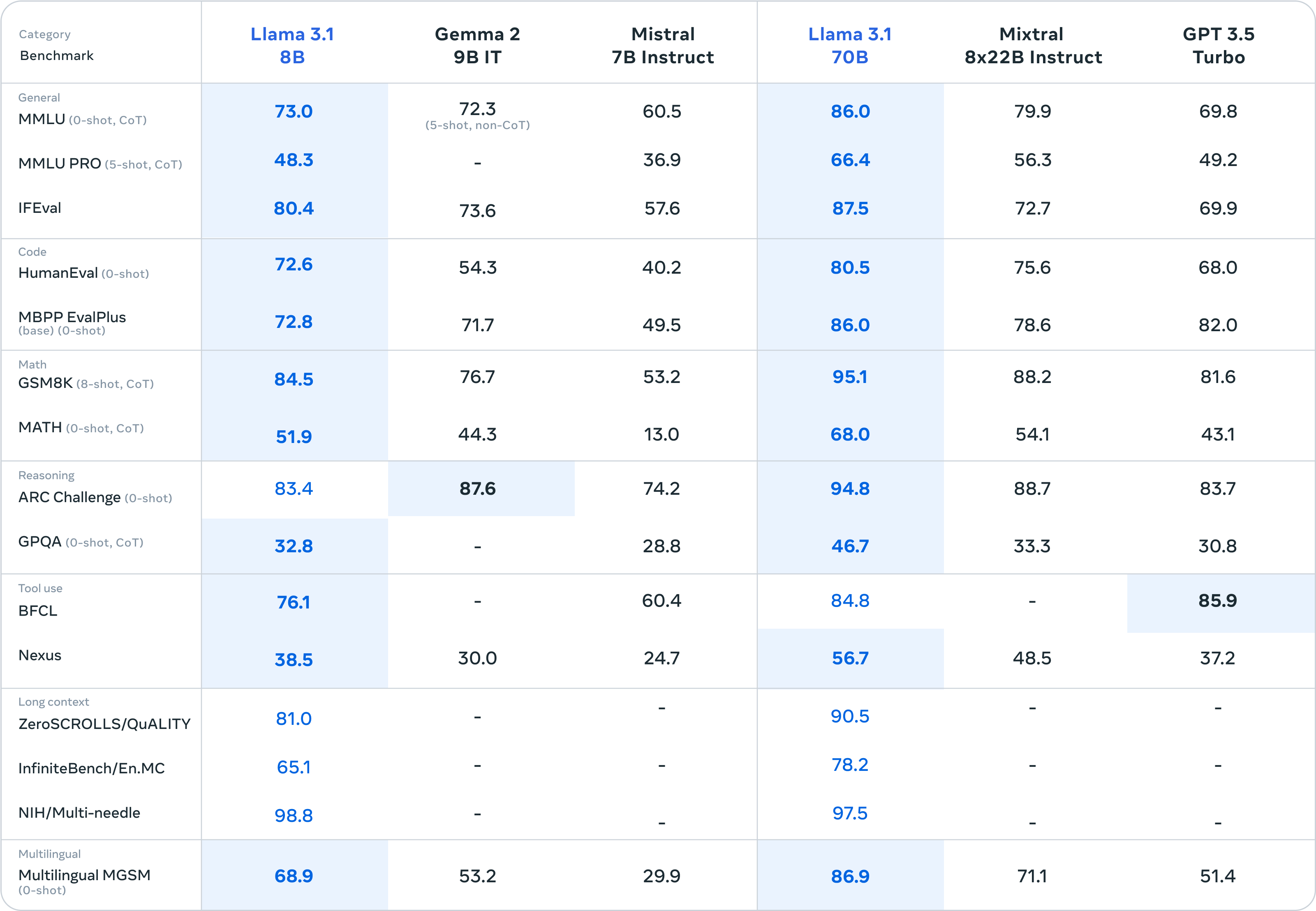
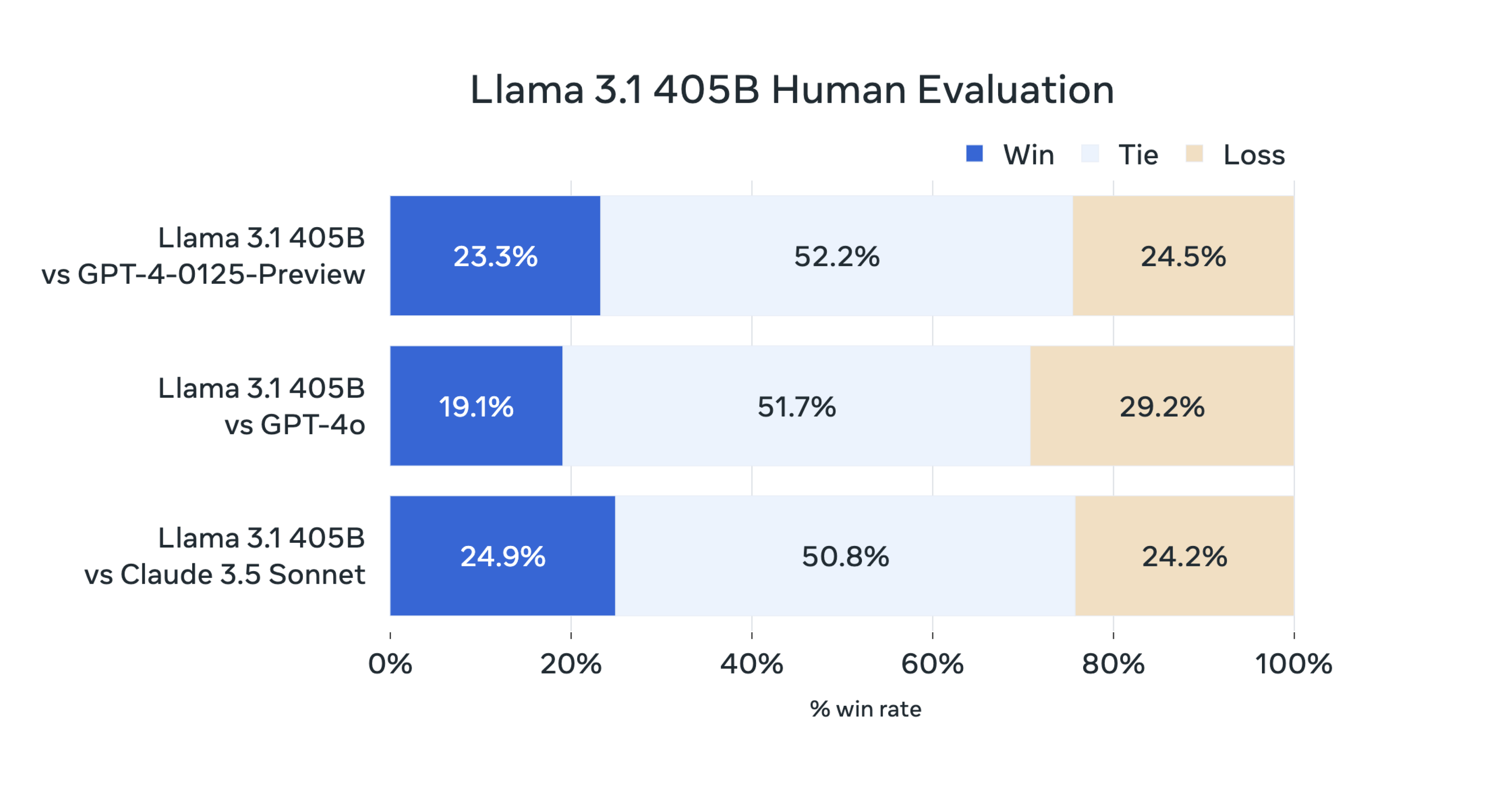
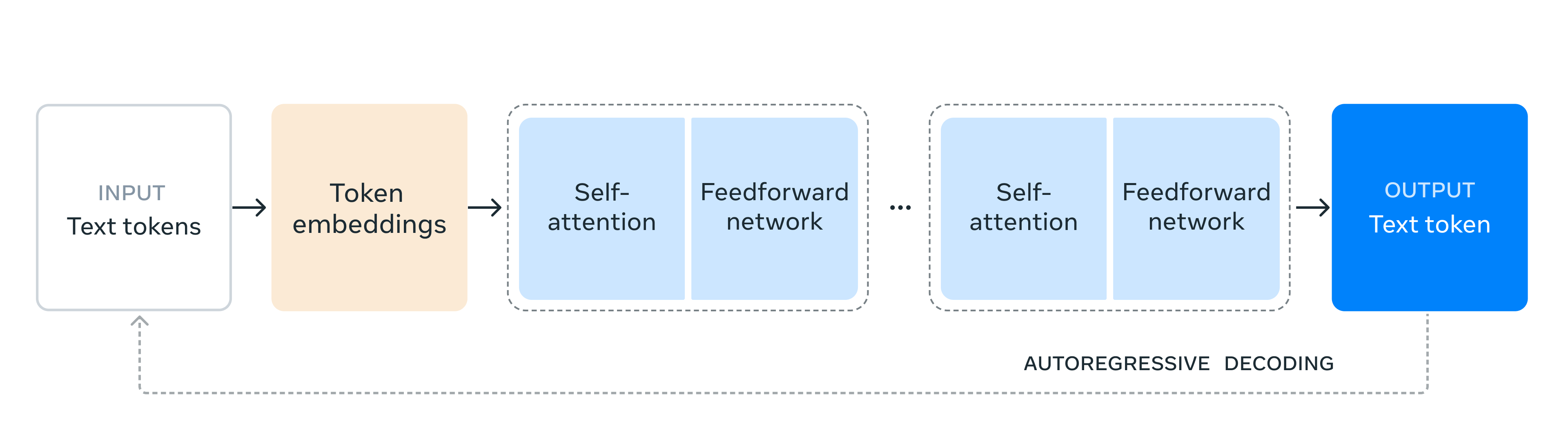
As our largest model yet, training Llama 3.1 405B on over 15 trillion tokens was a major challenge. To enable training runs at this scale and achieve the results we have in a reasonable amount of time, we significantly optimized our full training stack and pushed our model training to over 16 thousand H100 GPUs, making the 405B the first Llama model trained at this scale.
Official Meta News & Documentation
- https://llama.meta.com/
- https://ai.meta.com/blog/meta-llama-3-1/
- https://llama.meta.com/docs/overview
- https://llama.meta.com/llama-downloads/
- https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md
See also: The Llama 3 Herd of Models paper here:
HuggingFace Download Links
8B
Meta-Llama-3.1-8B
Meta-Llama-3.1-8B-Instruct
Llama-Guard-3-8B
Llama-Guard-3-8B-INT8
70B
Meta-Llama-3.1-70B
Meta-Llama-3.1-70B-Instruct
405B
Meta-Llama-3.1-405B-FP8
Meta-Llama-3.1-405B-Instruct-FP8
Meta-Llama-3.1-405B
Meta-Llama-3.1-405B-Instruct
Getting the models
You can download the models directly from Meta or one of our download partners: Hugging Face or Kaggle.
Alternatively, you can work with ecosystem partners to access the models through the services they provide. This approach can be especially useful if you want to work with the Llama 3.1 405B model.
Note: Llama 3.1 405B requires significant storage and computational resources, occupying approximately 750GB of disk storage space and necessitating two nodes on MP16 for inferencing.
Learn more at:
Running the models
Linux
Windows
Mac
Cloud
More guides and resources
How-to Fine-tune Llama 3.1 models
Quantizing Llama 3.1 models
Prompting Llama 3.1 models
Llama 3.1 recipes
YouTube media
Rowan Cheung - Mark Zuckerberg on Llama 3.1, Open Source, AI Agents, Safety, and more
Matthew Berman - BREAKING: LLaMA 405b is here! Open-source is now FRONTIER!
Wes Roth - Zuckerberg goes SCORCHED EARTH.... Llama 3.1 BREAKS the "AGI Industry"*
1littlecoder - How to DOWNLOAD Llama 3.1 LLMs
Bloomberg - Inside Mark Zuckerberg's AI Era | The Circuit
Hello everyone. Today I'd like to catch up on another paper, a popular one that has pushed a new fine-tuning trend called DPO (Direct Preference Optimization).
Included with the paper are a few open-source projects and code repos that support DPO training. If you are fine-tuning models, this is worth looking into!
DPO Arxiv Paper
Try Fine-tuning w/ DPO using Axolotl
Try Fine-tuning w/ DPO using Llama Factory
Try Fine-tuning w/DPO using Unsloth
Now.. onto the paper!
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining such steerability collect human labels of the relative quality of model generations and fine-tune the unsupervised LM to align with these preferences, often with reinforcement learning from human feedback (RLHF).
However, RLHF is a complex and often unstable procedure, first fitting a reward model that reflects the human preferences, and then fine-tuning the large unsupervised LM using reinforcement learning to maximize this estimated reward without drifting too far from the original model.
In this paper we introduce a new parameterization of the reward model in RLHF that enables extraction of the corresponding optimal policy in closed form, allowing us to solve the standard RLHF problem with only a simple classification loss.
The resulting algorithm, which we call Direct Preference Optimization (DPO), is stable, performant, and computationally lightweight, eliminating the need for sampling from the LM during fine-tuning or performing significant hyperparameter tuning. Our experiments show that DPO can fine-tune LMs to align with human preferences as well as or better than existing methods.
Notably, fine-tuning with DPO exceeds PPO-based RLHF in ability to control sentiment of generations, and matches or improves response quality in summarization and single-turn dialogue while being substantially simpler to implement and train.

Figure 1: DPO optimizes for human preferences while avoiding reinforcement learning. Existing methods for fine-tuning language models with human feedback first fit a reward model to a dataset of prompts and human preferences over pairs of responses, and then use RL to find a policy that maximizes the learned reward. In contrast, DPO directly optimizes for the policy best satisfying the preferences with a simple classification objective, fitting an implicit reward model whose corresponding optimal policy can be extracted in closed form

Figure 2: Left. The frontier of expected reward vs KL to the reference policy. DPO provides the highest expected reward for all KL values, demonstrating the quality of the optimization.
Right. TL;DR summarization win rates vs. human-written summaries, using GPT-4 as evaluator. DPO exceeds PPO’s best-case performance on summarization, while being more robust to changes in the sampling temperature.
Learning from preferences is a powerful, scalable framework for training capable, aligned language models. We have introduced DPO, a simple training paradigm for training language models from preferences without reinforcement learning.
Rather than coercing the preference learning problem into a standard RL setting in order to use off-the-shelf RL algorithms, DPO identifies a mapping between language model policies and reward functions that enables training a language model to satisfy human preferences directly, with a simple cross-entropy loss, without reinforcement learning or loss of generality.
With virtually no tuning of hyperparameters, DPO performs similarly or better than existing RLHF algorithms, including those based on PPO; DPO thus meaningfully reduces the barrier to training more language models from human preferences.
Our results raise several important questions for future work. How does the DPO policy generalize out of distribution, compared with learning from an explicit reward function?
Our initial results suggest that DPO policies can generalize similarly to PPO-based models, but more comprehensive study is needed. For example, can training with self-labeling from the DPO policy similarly make effective use of unlabeled prompts? On another front, how does reward over-optimization manifest in the direct preference optimization setting, and is the slight decrease in performance in Figure 3-right an instance of it?
Additionally, while we evaluate models up to 6B parameters, exploration of scaling DPO to state-of-the-art models orders of magnitude larger is an exciting direction for future work. Regarding evaluations, we find that the win rates computed by GPT-4 are impacted by the prompt; future work may study the best way to elicit high-quality judgments from automated systems. Finally, many possible applications of DPO exist beyond training language models from human preferences, including training generative models in other modalities.
Hello everyone, I have another exciting Mamba paper to share. This being an MoE implementation of the state space model.
For those unacquainted with Mamba, let me hit you with a double feature (take a detour checking out these papers/code if you don't know what Mamba is):
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- Official Mamba GitHub
- Example Implementation - Mamba-Chat
Now.. onto the MoE paper!
MoE-Mamba
Efficient Selective State Space Models with Mixture of Experts
Maciej Pióro, Kamil Ciebiera, Krystian Król, Jan Ludziejewski, Sebastian Jaszczur
State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based LLMs, including recent state-of-the-art open-source models.
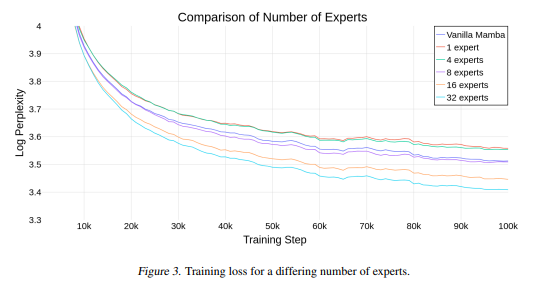
We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance.
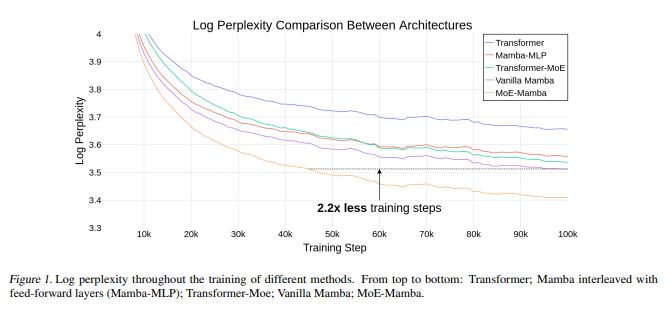
Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer.
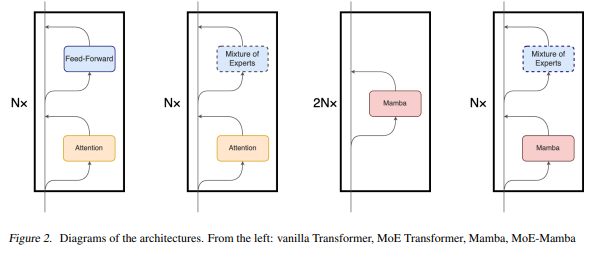
| Category | Hyperparameter | Value |
|---|---|---|
| Model | Total Blocks | 8 (16 in Mamba) |
| dmodel | 512 | |
| Feed-Forward | df f | 2048 (with Attention) or 1536 (with Mamba) |
| Mixture of Experts | dexpert | 2048 (with Attention) or 1536 (with Mamba) |
| Experts | 32 | |
| Attention | nheads | 8 |
| Training | Training Steps | 100k |
| Context Length | 256 | |
| Batch Size | 256 | |
| LR | 1e-3 | |
| LR Warmup | 1% steps | |
| Gradient Clipping | 0.5 |
MoE seems like the logical way to move forward with Mamba, at this point, I'm wondering could there anything else holding it back? Curious to see more tools and implementations compare against some of the other trending transformer-based LLM stacks.
Hello everyone, I have a very exciting paper to share with you today. This came out a little while ago, (like many other papers since my hiatus) so allow me to catch you up if you haven't read it already.
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- Official Mamba GitHub
- Example Implementation - Mamba-Chat
- Bonus Paper: MoE-Mamba
Mamba
Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu, Tri Dao

Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module.
Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language.
We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements.
First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token.
Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba).
Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences.
As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics.
On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
(...) Mamba achieves state-of-the-art results on a diverse set of domains, where it matches or exceeds the performance of strong Transformer models. We are excited about the broad applications of selective state space models to build foundation models for different domains, especially in emerging modalities requiring long context such as genomics, audio, and video. Our results suggest that Mamba is a strong candidate to be a general sequence model backbone.
What are your thoughts on Mamba?
I appreciate this comment more than you will know. Thanks for sharing your thoughts.
It’s been a challenge realizing this time capsule is more than that - but a grassroots community and open-source project bigger than me. Adjusting the content to reflect shared interests has been a concept I have grappled with these last few weeks - especially as we exit some of the exciting innovations we saw earlier this year.
I think the type of content series you mention is the next step here - that being practical and pragmatic insights that illustrate / enable new workflows and applications.
That being said, this type of content creation will likely take more time than the journalistic reporting I’ve been doing - but I think it’s absolutely worth the effort and the next logical evolution of whatever this forum becomes.
Thanks again for your kind words. I work 5/6 day weeks in my tech job on top of this, so burnout is a real thing. I think I’ll go for a hike this week and reevaluate how to best proliferate and spread FOSAI.
If you’re reading this now and have ideas of your own - I’m all ears.
On my journey working on fine-tuning a model for [email protected] I stumbled across https://brev.dev/.
If you're looking at fine-tuning an LLM of your own - you should definitely give this platform a look. If not for the GPUs, at least for the other resources and guides. They support GPU powered notebooks, which is a feature I look for in these platforms. Their biome is also really helpful when you're looking to hack away at a prototype fast.
I am still testing it out, but I'd be keen to hear others opinions on it too.
brev dev prices (est):

Aside from the cloud GPU broker platform, they host a ton of really helpful guides and resources that you might be interested in. Check out their blog for more info. A few posts highlighted below.
- A Guide to Cost-Effectively Fine-Tuning Mistral
- How to fine-tune Llama 2 on your own data
- What you need to know about CUDA to get things done on Nvidia GPUs
- Run ControlNet on Stable Diffusion WebUI
- ..and More!
Let me know if you like brev or if there's another tool/workflow/process or platform you use that could enable others to fine-tune models of their own. Curious to see what else is out there!
This is on the horizon - I will definitely be making a post on the workflow and process once it is figured out.
I am actively exploring this question.
So far - it’s been the best performing 7B model I’ve been able to get my hands on. Anyone running consumer hardware could get a GGUF version running on almost any dedicated GPU/CPU combo.
I am a firm believer there is more performance and better quality of responses to be found in smaller parameter models. Not too mention interesting use cases you could apply fine-tuning an ensemble approach.
A lot of people sleep on 7B, but I think Mistral is a little different - there’s a lot of exploring to be had finding these use cases but I think they’re out there waiting to be discovered.
I’ll definitely report back on how the first attempt at fine-tuning this myself goes. Until then, I suppose it would be great for any roleplay or basic chat interaction. Given it’s low headroom - it’s much more lightweight to prototype with outside of the other families and model sizes.
If anyone else has a particular use case for 7B models - let us know here. Curious to know what others are doing with smaller params.
What I find interesting is how useful these tools are (even with the imperfections that you mention). Imagine a world where this level of intelligence has a consistent low error rate.
Semantic computation and agentic function calling with this level of accuracy will revolutionize the world. It’s only a matter of time, adoption, and availability.
I respect your honesty.
Google has absolutely tanked for me these last few years. It revolutionized the world by revolutionizing search. But ChatGPT has done the same, now better - and in a much more interesting way.
I’ll take a 10 second prompt process over 20 minutes of hunting down (advertised) paged results any day of the week.
I have learned everything I have about AI through AI mentors.
Having the ability to ask endless amounts of seemingly stupid questions does a lot for me.
Not to mention some of the analogies and abstractions you can utilize to build your own learning process.
I’d love to see schools start embracing the power of personalized mentors for each and every student. I think some of the first universities to embrace this methodology will produce some incredible minds.
You should try fine-tuning that legalese model! I know I’d use it. Could be a great business idea or generally helpful for anyone you release it to.
I cannot understate how nice it is having a coding assistant 24/7.
I’m curious to see how projects like ChatDev evolve over time. I think agentic tooling is going to take us to some very sci-fi looking territory.
Semantic computation is the future.
I never considered 8 - 11. Those are really interesting use cases. I’m with you on every other point. I’m particularly interested in solving the messy unstructured notes scenario. I really feel you on that one. I’ll see what I can do!
What I find particularly exciting is that we’re seeing this evolution in real-time.
Can you imagine what these models might look like in 2 years? 5? 10?
There is a remarkable future on the horizon. I hope everyone gets an equal chance to be a part of it.
view more: next ›
What sort of tokens per second are you seeing with your hardware? Mind sharing some notes on what you're running there? Super curious!