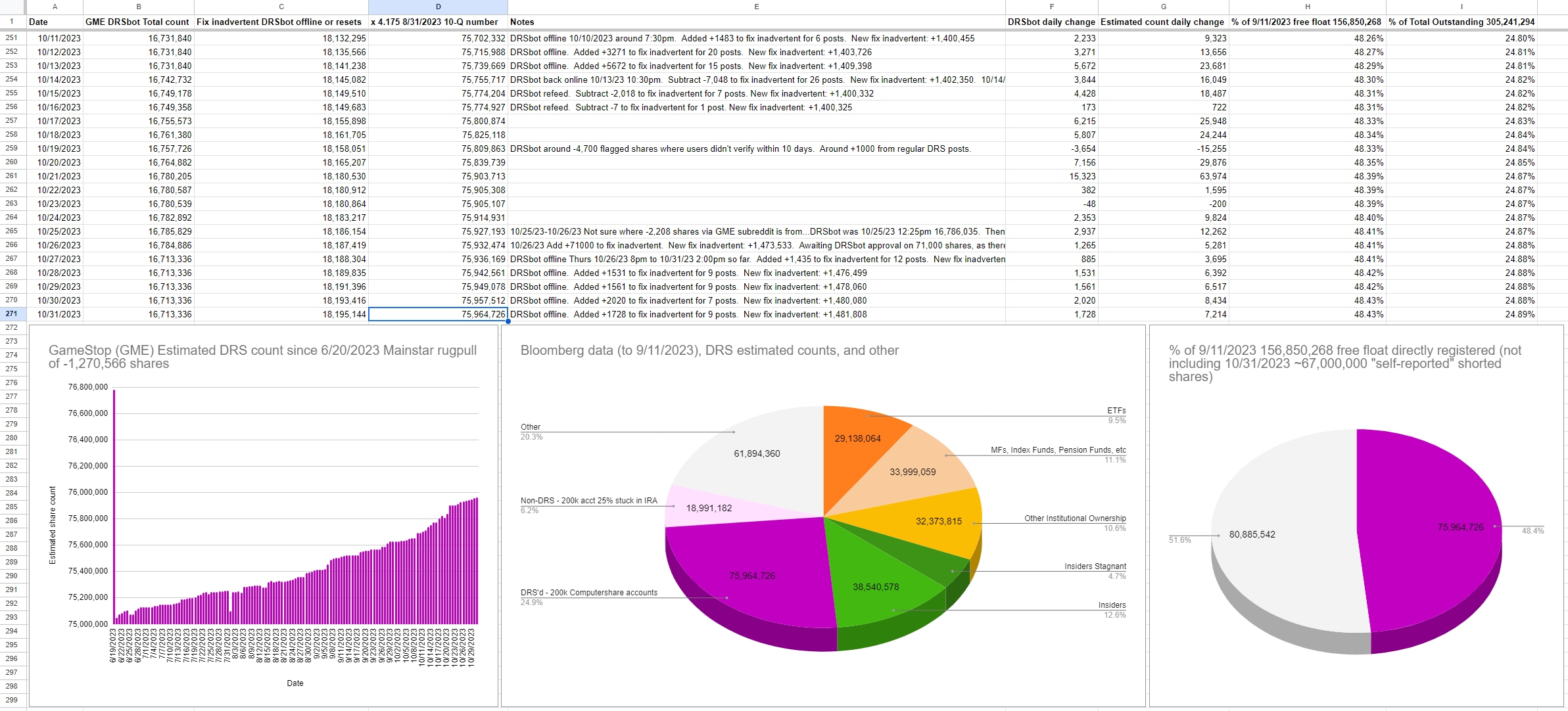
10/31/2023 Estimated DRS count: 75,964,726 ((using today's DRSbot total + fix inadvertent DRSbot offline or resets) x 4.175)
The 4.175 multiplier comes from 8/31/2023 Form 10-Q divided by DRSbot 8/31/2023 total: 75,400,000 / 18,059,540 = 4.175
Bloomberg data (to 9/11/2023), DRS estimated counts, and other:
| Holding | Number of shares | As of |
|---|---|---|
| ETFs | 29,138,064 | 9/8/2023 |
| MFs, Index Funds, Pension Funds, etc | 33,999,059 | 9/8/2023 |
| Other Institutional Ownership | 32,373,815 | 9/8/2023 |
| Insiders Stagnant | 14,339,510 | 9/8/2023 |
| Insiders | 38,540,578 | 9/11/2023 |
| DRS'd - 200k Computershare accounts | 75,964,726 | 10/31/2023 |
| Non-DRS - 200k acct 25% stuck in IRA | 18,991,182 | 10/31/2023 |
| Other | 61,894,360 | 10/31/2023 |
- Total Outstanding on 8/31/2023: 305,241,294
- Free float on 9/11/2023: 156,850,268
- Thank you to lawsondt for the Bloomberg data to 9/8/2023.
- Added Larry +6000 and Alain +15000 to Insiders number on 9/11/2023.
- "Non-DRS - 200k acct 25% stuck in IRA" is a conservative percentage. The Google share count surveys have suggested the 200k Computershare accounts have 30-40% additional shares stuck in IRAs.
- "Fix inadvertent DRSbot offline or resets" is primarily whale #1's 1,388,490 DRS shares. Long story of switching subs and losing their DRS share count. So added the "fix inadvertent" column to capture their DRS shares.