this post was submitted on 02 Aug 2024
1469 points (98.4% liked)
Science Memes
11047 readers
3053 users here now
Welcome to c/science_memes @ Mander.xyz!
A place for majestic STEMLORD peacocking, as well as memes about the realities of working in a lab.

Rules
- Don't throw mud. Behave like an intellectual and remember the human.
- Keep it rooted (on topic).
- No spam.
- Infographics welcome, get schooled.
This is a science community. We use the Dawkins definition of meme.
Research Committee
Other Mander Communities
Science and Research
Biology and Life Sciences
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- !reptiles and [email protected]
Physical Sciences
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
- [email protected]
Humanities and Social Sciences
Practical and Applied Sciences
- !exercise-and [email protected]
- [email protected]
- !self [email protected]
- [email protected]
- [email protected]
- [email protected]
Memes
Miscellaneous
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
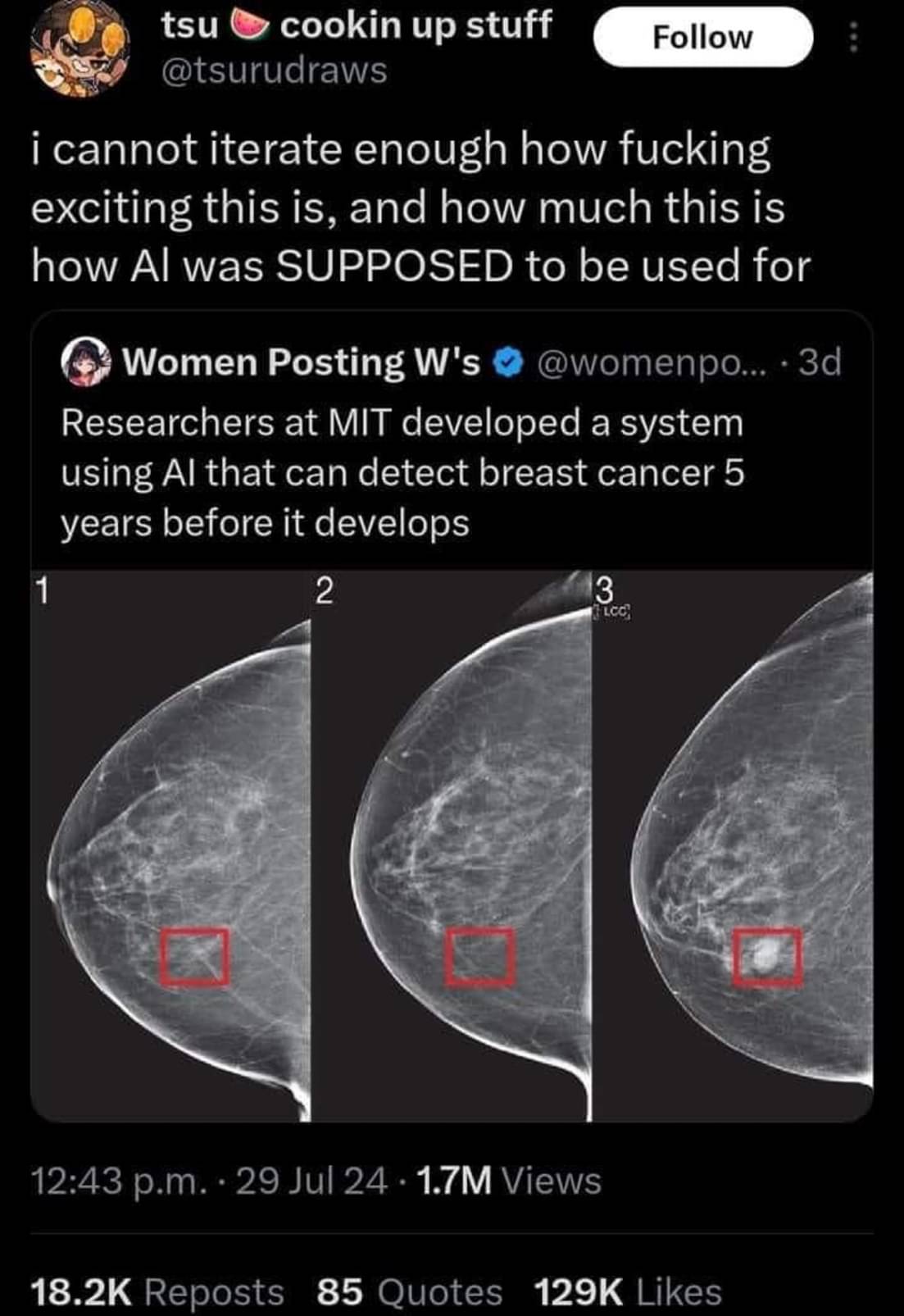
The only "innovation" here is feeding full view mammograms to a ResNet18(2016 model). The traditional risk factors regression is nothing special (barely machine learning). They don't go in depth about how they combine the two for the hybrid model, ~~so it's probably safe to assume it is something simple (merely combining the results, so nothing special in the training step).~~ edit: I stand corrected, commenter below pointed out the appendix, and the regression does in fact come into play in the training step
As a different commenter mentioned, the data collection is largely the interesting part here.
I'll admit I was wrong about my first guess as to the network topology used though, I was thinking they used something like auto encoders (but that is mostly used in cases where examples of bad samples are rare)
Actually they did, it's in Appendix E (PDF warning) . A GitHub repo would have been nice, but I think there would be enough info to replicate this if we had the data.
Yeah it's not the most interesting paper in the world. But it's still a cool use IMO even if it might not be novel enough to deserve a news article.
ResNet18 is ancient and tiny…I don’t understand why they didn’t go with a deeper network. ResNet50 is usually the smallest I’ll use.