this post was submitted on 15 Jun 2024
30 points (100.0% liked)
SneerClub
1011 readers
1 users here now
Hurling ordure at the TREACLES, especially those closely related to LessWrong.
AI-Industrial-Complex grift is fine as long as it sufficiently relates to the AI doom from the TREACLES. (Though TechTakes may be more suitable.)
This is sneer club, not debate club. Unless it's amusing debate.
[Especially don't debate the race scientists, if any sneak in - we ban and delete them as unsuitable for the server.]
founded 2 years ago
MODERATORS
you are viewing a single comment's thread
view the rest of the comments
view the rest of the comments
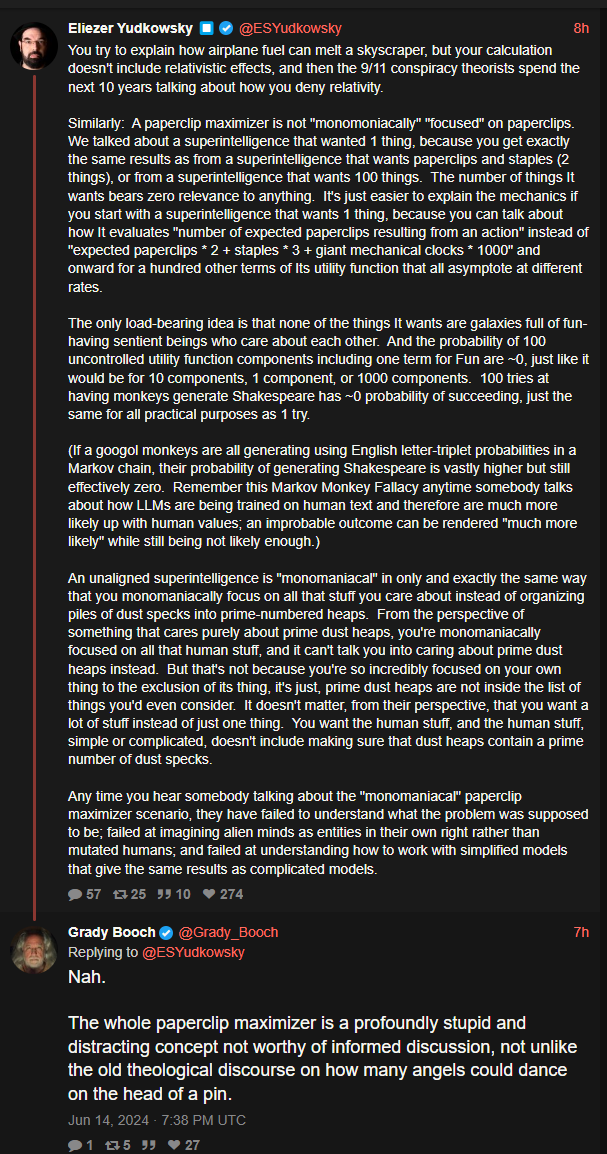
Big Yud: You try to explain how airplane fuel can melt a skyscraper, but your calculation doesn't include relativistic effects, and then the 9/11 conspiracy theorists spend the next 10 years talking about how you deny relativity.
Similarly: A paperclip maximizer is not "monomoniacally" "focused" on paperclips. We talked about a superintelligence that wanted 1 thing, because you get exactly the same results as from a superintelligence that wants paperclips and staples (2 things), or from a superintelligence that wants 100 things. The number of things It wants bears zero relevance to anything. It's just easier to explain the mechanics if you start with a superintelligence that wants 1 thing, because you can talk about how It evaluates "number of expected paperclips resulting from an action" instead of "expected paperclips * 2 + staples * 3 + giant mechanical clocks * 1000" and onward for a hundred other terms of Its utility function that all asymptote at different rates.
The only load-bearing idea is that none of the things It wants are galaxies full of fun-having sentient beings who care about each other. And the probability of 100 uncontrolled utility function components including one term for Fun are ~0, just like it would be for 10 components, 1 component, or 1000 components. 100 tries at having monkeys generate Shakespeare has ~0 probability of succeeding, just the same for all practical purposes as 1 try.
(If a googol monkeys are all generating using English letter-triplet probabilities in a Markov chain, their probability of generating Shakespeare is vastly higher but still effectively zero. Remember this Markov Monkey Fallacy anytime somebody talks about how LLMs are being trained on human text and therefore are much more likely up with human values; an improbable outcome can be rendered "much more likely" while still being not likely enough.)
An unaligned superintelligence is "monomaniacal" in only and exactly the same way that you monomaniacally focus on all that stuff you care about instead of organizing piles of dust specks into prime-numbered heaps. From the perspective of something that cares purely about prime dust heaps, you're monomaniacally focused on all that human stuff, and it can't talk you into caring about prime dust heaps instead. But that's not because you're so incredibly focused on your own thing to the exclusion of its thing, it's just, prime dust heaps are not inside the list of things you'd even consider. It doesn't matter, from their perspective, that you want a lot of stuff instead of just one thing. You want the human stuff, and the human stuff, simple or complicated, doesn't include making sure that dust heaps contain a prime number of dust specks.
Any time you hear somebody talking about the "monomaniacal" paperclip maximizer scenario, they have failed to understand what the problem was supposed to be; failed at imagining alien minds as entities in their own right rather than mutated humans; and failed at understanding how to work with simplified models that give the same results as complicated models