1
DevOps
831 readers
1 users here now
Development & operations
founded 5 years ago
MODERATORS
2
3
4
6
7
8
{kind=link}
10
cross-posted from: https://lemmy.ml/post/4079840
"Don't repeat yourself. Make Make make things happen for you!" 😎
I just created a public room dedicated to all things about Make and Makefiles.
#.mk:matrix.org
or
matrix.to/#/#.mk:matrix.orgHope to see you there.

11
12
13
14
15
16
17
18
cross-posted from [email protected]: https://group.lt/post/46385
Adopting DevOps practices is nowadays a recurring task in the industry. DevOps is a set of practices intended to reduce the friction between the software development (Dev) and the IT operations (Ops), resulting in higher quality software and a shorter development lifecycle. Even though many resources are talking about DevOps practices, they are often inconsistent with each other on the best DevOps practices. Furthermore, they lack the needed detail and structure for beginners to the DevOps field to quickly understand them.
In order to tackle this issue, this paper proposes four foundational DevOps patterns: Version Control Everything, Continuous Integration, Deployment Automation, and Monitoring. The patterns are both detailed enough and structured to be easily reused by practitioners and flexible enough to accommodate different needs and quirks that might arise from their actual usage context. Furthermore, the patterns are tuned to the DevOps principle of Continuous Improvement by containing metrics so that practitioners can improve their pattern implementations.
The article does not describes but actually identified and included 2 other patterns in addition to the four above (so actually 6):
- Cloud Infrastructure, which includes cloud computing, scaling, infrastructure as a code, ...
- Pipeline, "important for implementing Deployment Automation and Continuous Integration, and segregating it from the others allows us to make the solutions of these patterns easier to use, namely in contexts where a pipeline does not need to be present."
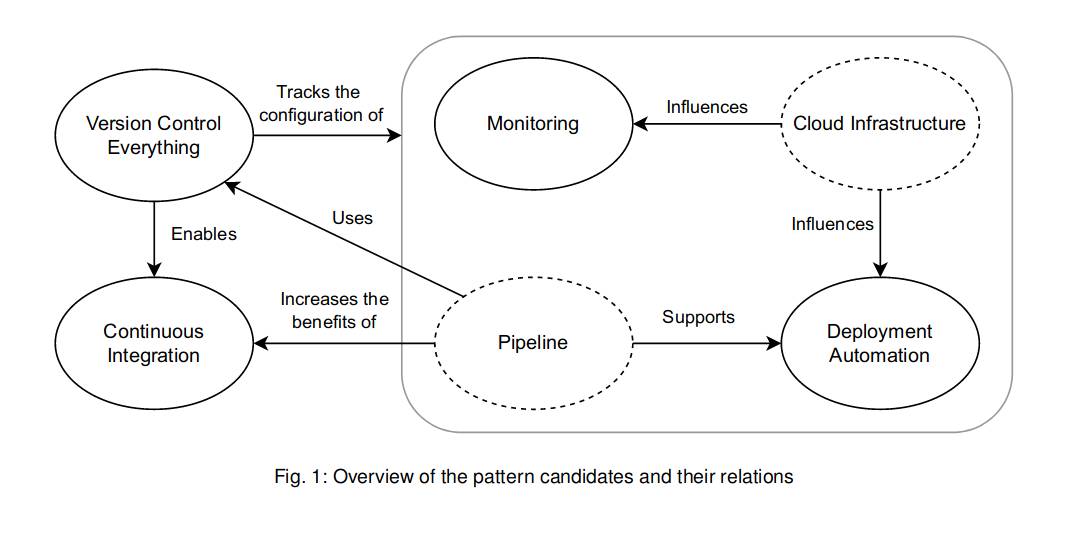
The paper is interesting for the following structure in describing the patterns:
- Name: An evocative name for the pattern.
- Context: Contains the context for the pattern providing a background for the problem.
- Problem: A question representing the problem that the pattern intends to solve.
- Forces: A list of forces that the solution must balance out.
- Solution: A detailed description of the solution for our pattern’s problem.
- Consequences: The implications, advantages and trade-offs caused by using the pattern.
- Related Patterns: Patterns which are connected somehow to the one being described.
- Metrics: A set of metrics to measure the effectiveness of the pattern’s solution implementation.
19
20
21
22
23
24
25
view more: next ›